When I initially spinned up my k8s cluster, I got everything working but I always experienced network disconnects. it turns out it’s due to my NIC. It was quite difficult to notice this or maybe I just really never doubted my hypervisor and the hardware. Eventually I thought of checking the dmesg logs from within proxmox.
Sep 29 14:54:58 pve1 kernel: e1000e 0000:00:1f.6 eno1: Detected Hardware Unit Hang:
TDH <22>
TDT <bb>
next_to_use <bb>
next_to_clean <22>
buffer_info[next_to_clean]:
time_stamp <100cb7acb>
next_to_watch <23>
jiffies <100cb7d99>
next_to_watch.status <0>
MAC Status <80083>
PHY Status <796d>
PHY 1000BASE-T Status <3800>
PHY Extended Status <3000>
PCI Status <10>
...
...
...
Sep 29 14:55:07 pve1 kernel: e1000e 0000:00:1f.6 eno1: Reset adapter unexpectedly
Sep 29 14:55:07 pve1 kernel: vmbr0: port 1(eno1) entered disabled state
Sep 29 14:55:07 pve1 kernel: vmbr0v20: port 1(eno1.20) entered disabled state
Sep 29 14:55:07 pve1 kernel: vmbr0v30: port 1(eno1.30) entered disabled state
Sep 29 14:55:11 pve1 kernel: e1000e 0000:00:1f.6 eno1: NIC Link is Up 1000 Mbps Full Duplex, Flow Control: None
Sep 29 14:55:11 pve1 kernel: vmbr0: port 1(eno1) entered blocking state
Sep 29 14:55:11 pve1 kernel: vmbr0: port 1(eno1) entered forwarding state
Sep 29 14:55:11 pve1 kernel: vmbr0v20: port 1(eno1.20) entered blocking state
Sep 29 14:55:11 pve1 kernel: vmbr0v20: port 1(eno1.20) entered forwarding state
Sep 29 14:55:11 pve1 kernel: vmbr0v30: port 1(eno1.30) entered blocking state
Sep 29 14:55:11 pve1 kernel: vmbr0v30: port 1(eno1.30) entered forwarding state
When I saw these messages I thought my switch was acting up. I was almost ready to purchase a new switch but then upon further googling I landed in this forum post.
Turns out this specific model is known to be freezing from time to time when segmentation is done by the NIC. This comes enabled by default when installing Proxmox. A quick fix suggeested in the post which worked for me was to simply disable the TSO and GSO flags on the specific interface. On runtime this can be disabled by executing ethtool -K eno1 tso off gso off.
To make the changes permenant, the following line should be added in the /etc/network/interfaces file:
post-up /usr/bin/logger -p debug -t ifup "Disabling segmentation offload for eno1" && /sbin/ethtool -K $IFACE tso off gso off && /usr/bin/logger -p debug -t ifup "Disabled offload for eno1"
e.g.
One more issue I faced was very slow throughput when playing videos from Jellyfin.
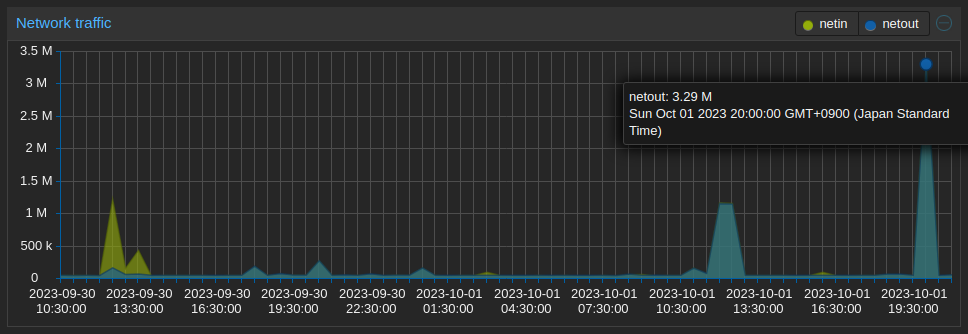
Noticed that throughput was very low regardless whether I’m using the docker traefik or the one in my kubernetes cluster, while the original traefik container on my Unraid
After drilling down that issue seems to be specific to my Proxmox node, I checked whether the 1Gbit/s speed was properly negotiated as suggested in this other forum post.
Executing ethtool eno1 showed me the following output:
root@pve1:~# ethtool eno1
Settings for eno1:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 10Mb/s
Duplex: Full
Auto-negotiation: on
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
MDI-X: on (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Disabled auto-negotiation and configured 1Gbit manually:
ethtool -s eno1 speed 1000 duplex full autoneg off
root@pve1:~# ethtool eno1
Settings for eno1:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 1000baseT/Full
Advertised pause frame use: No
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Auto-negotiation: on
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
MDI-X: off (auto)
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
After having these in place, my cluster has been running perfectly fine for almost a month now with nohiccups!