A couple of days ago I started facing Longhorn issues after rebooting all three nodes. For some reason my adguard deployment was stuck trying to mount the PV. I’m running my adguard deployment with RWX and this means it’s mounted over NFS.
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedMount 45m (x3 over 56m) kubelet Unable to attach or mount volumes: unmounted volumes=[adguard-conf-pv adguard-work-pv], unattached volumes=[], failed to process volumes=[]: timed out waiting for the condition
Warning FailedMount 16m (x23 over 61m) kubelet MountVolume.MountDevice failed for volume "adguard-work-pv" : rpc error: code = Internal desc = mount failed: exit status 32
Mounting command: /usr/local/sbin/nsmounter
Mounting arguments: mount -t nfs -o vers=4.1,noresvport,intr,hard 10.43.20.191:/adguard-work-pv /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/6c472e8b20509432a91f0d78010890b28fd5ebac0d9e85d0554ba7a69c9dccbd/globalmount
Output: mount.nfs: Protocol not supported
Warning FailedMount 6m50s (x21 over 61m) kubelet Unable to attach or mount volumes: unmounted volumes=[adguard-work-pv adguard-conf-pv], unattached volumes=[], failed to process volumes=[]: timed out waiting for the condition
Warning FailedMount 67s (x31 over 62m) kubelet MountVolume.MountDevice failed for volume "adguard-conf-pv" : rpc error: code = Internal desc = mount failed: exit status 32
Mounting command: /usr/local/sbin/nsmounter
Mounting arguments: mount -t nfs -o vers=4.1,noresvport,intr,hard 10.43.25.161:/adguard-conf-pv /var/lib/kubelet/plugins/kubernetes.io/csi/driver.longhorn.io/e5cf370525e8a07eda18f130064a2fb3712c6f4668904245d8622230e3defd8e/globalmount
Output: mount.nfs: Protocol not supported
At first I was having some doubt on the NFS package — if it got updated and started causing issues with Longhorn. But this wasn’t the case. Googling online landed me to one github issue that was opened fairly recently (link here). andrewheberle shared a comment about facing the same issue after upgrading the kernel to 5.15.0-94.
https://www.kolide.com/features/checks/ubuntu-unattended-upgrades
Checking my apt history, it looks like Ubuntu upgraded automatically last 8th of February: less /var/log/apt/history.log
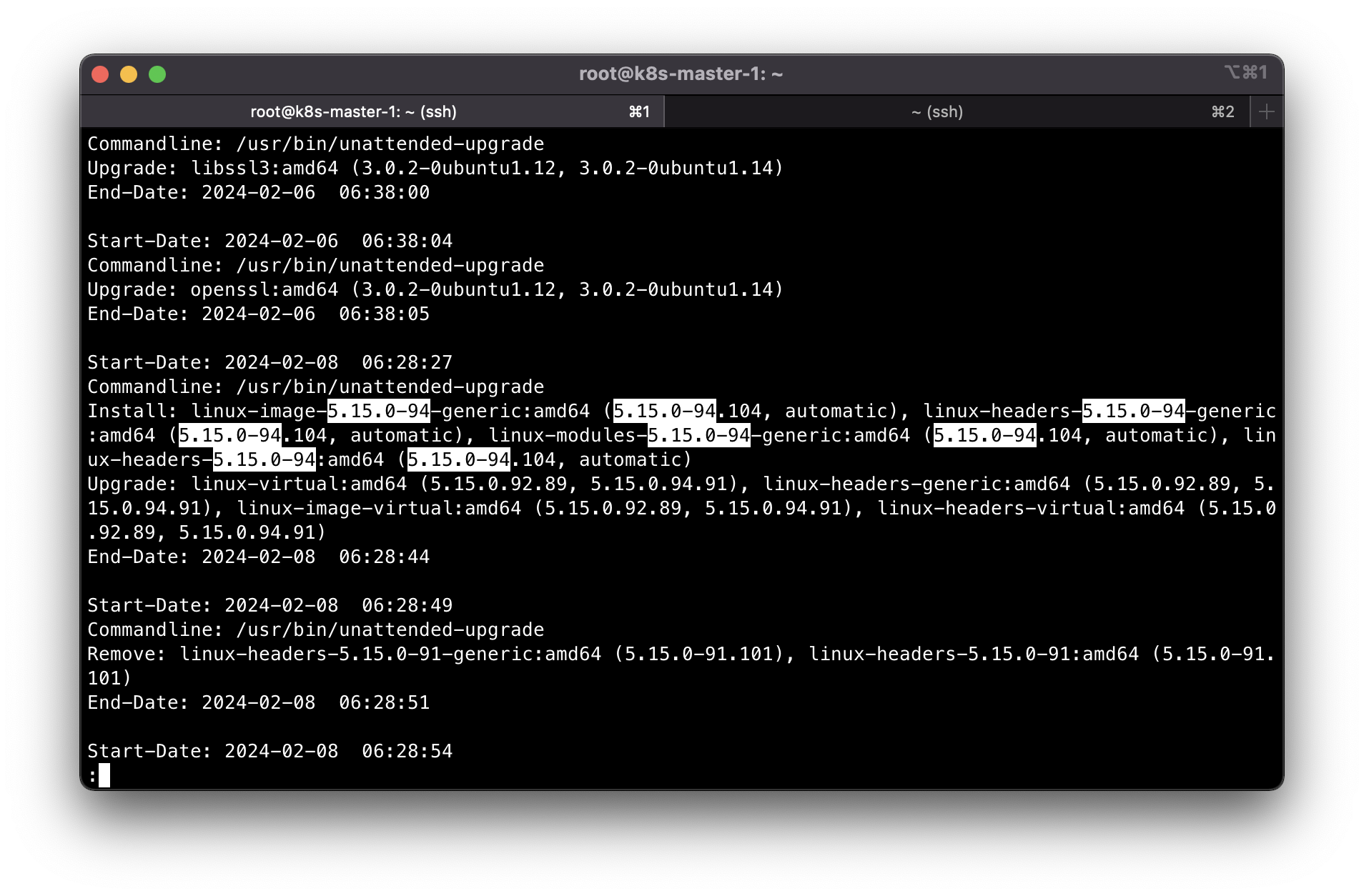
This looks to be due to unattended upgrades that are enabled by default upon OS installation.
You can check this by executing: cat /etc/apt/apt.conf.d/20auto-upgrades
APT::Periodic::Update-Package-Lists "1";
APT::Periodic::Unattended-Upgrade "1";
In my case I disabled both updating of package list and unattended upgrades by changing the value from 1 to 0.
Before we start the rollback, let’s check the available linux kernel images with dpkg -l | grep linux-image. We should be able to see our target kernel version. In this case 5.15.0-92 should be there.
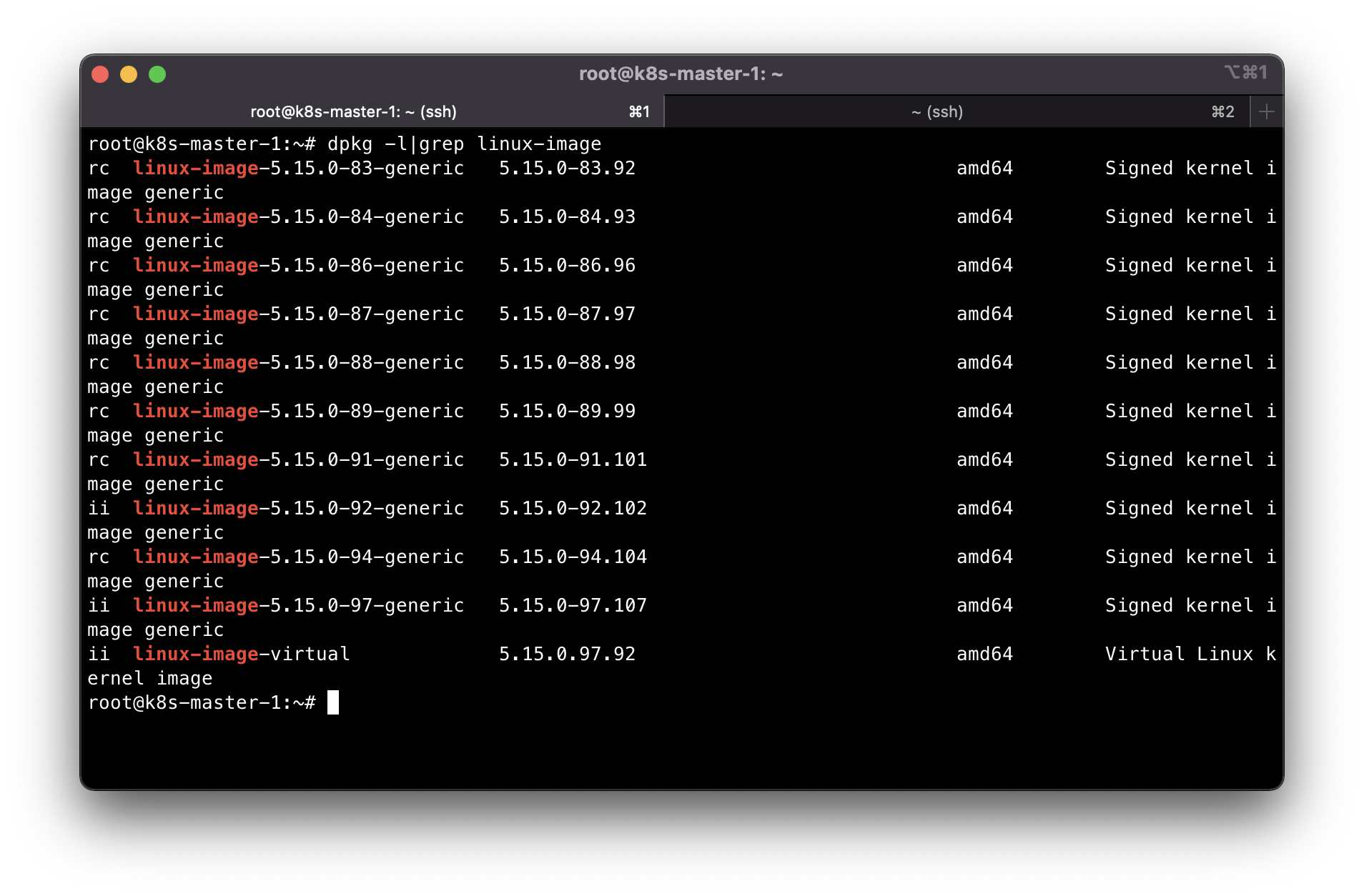
After verification then we can start uninstallation of the new kernel image. On the next reboot, the kernel should be running with the next latest available kernel version.
Refeferences:
- https://www.geekersdigest.com/how-to-downgrade-to-a-lower-kernel-version-in-ubuntu-linux/
- https://askubuntu.com/questions/1303568/downgrade-kernel-by-deleting-new-one-from-boot
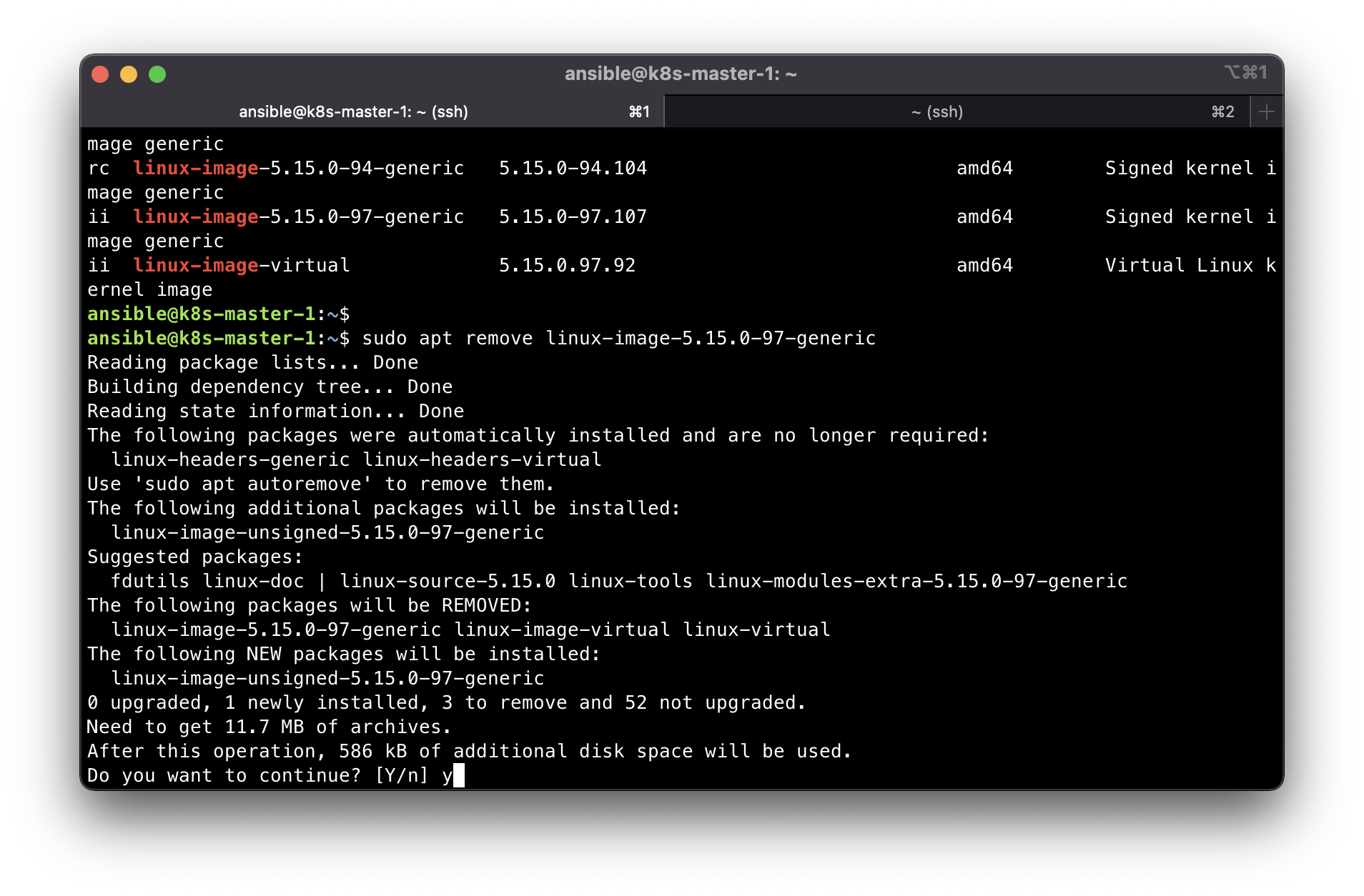
sudo apt remove linux-headers-5.15.0-97-generic -y
sudo apt remove linux-headers-5.15.0-97 linux-headers-5.15.0-97-generic linux-modules-5.15.0-97-generic linux-image-unsigned-5.15.0-97-generic -y
sudo apt remove linux-headers-5.15.0-94-generic -y
sudo apt remove linux-headers-5.15.0-94 linux-headers-5.15.0-94-generic linux-modules-5.15.0-94-generic linux-image-unsigned-5.15.0-94-generic -y
# then reboot
sudo shutdown -r now
Post reboot check the version:
uname -r
The longhorn volumes are also successfully mounted this time with no errors.
P.S. This known issue seems to be logged already in this Longhorn KB article